AMD Zen 3 Ryzen Deep Dive Review: 5950X, 5900X, 5800X and 5600X Tested
by Dr. Ian Cutress on November 5, 2020 9:01 AM ESTSection by Andrei Frumusanu
The New Zen 3 Core: Front-End Updates
Moving on, let’s see what makes the Zen3 microarchitecture tick and how detail on how it actually improves things compared to its predecessor design, starting off with the front-end of the core which includes branch prediction, decode, the OP-cache path and instruction cache, and the dispatch stage.
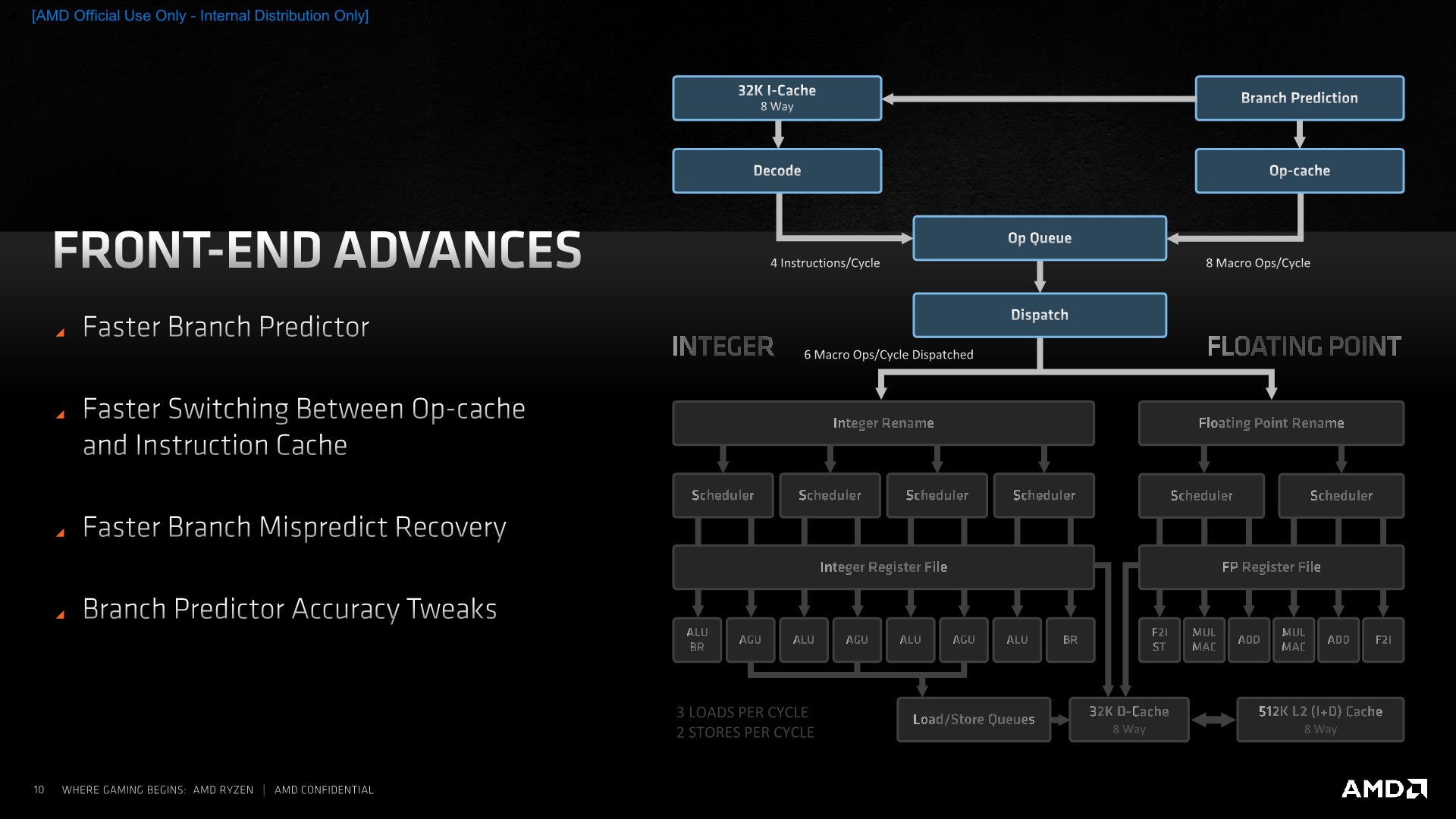
From a high-level overview, Zen3’s front-end looks the same as on Zen2, at least from a block-diagram perspective. The fundamental building blocks are the same, starting off with the branch-predictor unit which AMD calls state-of-the-art. This feeds into a 32KB instruction cache which forwards instructions into a 4-wide decode block. We’re still maintaining a two-way flow into the OP-queue, as when we see instructions again which have been previously decoded, they are then stored in the OP-cache from which they can be retrieved with a greater bandwidth (8 Mops/cycle) and with less power consumption.
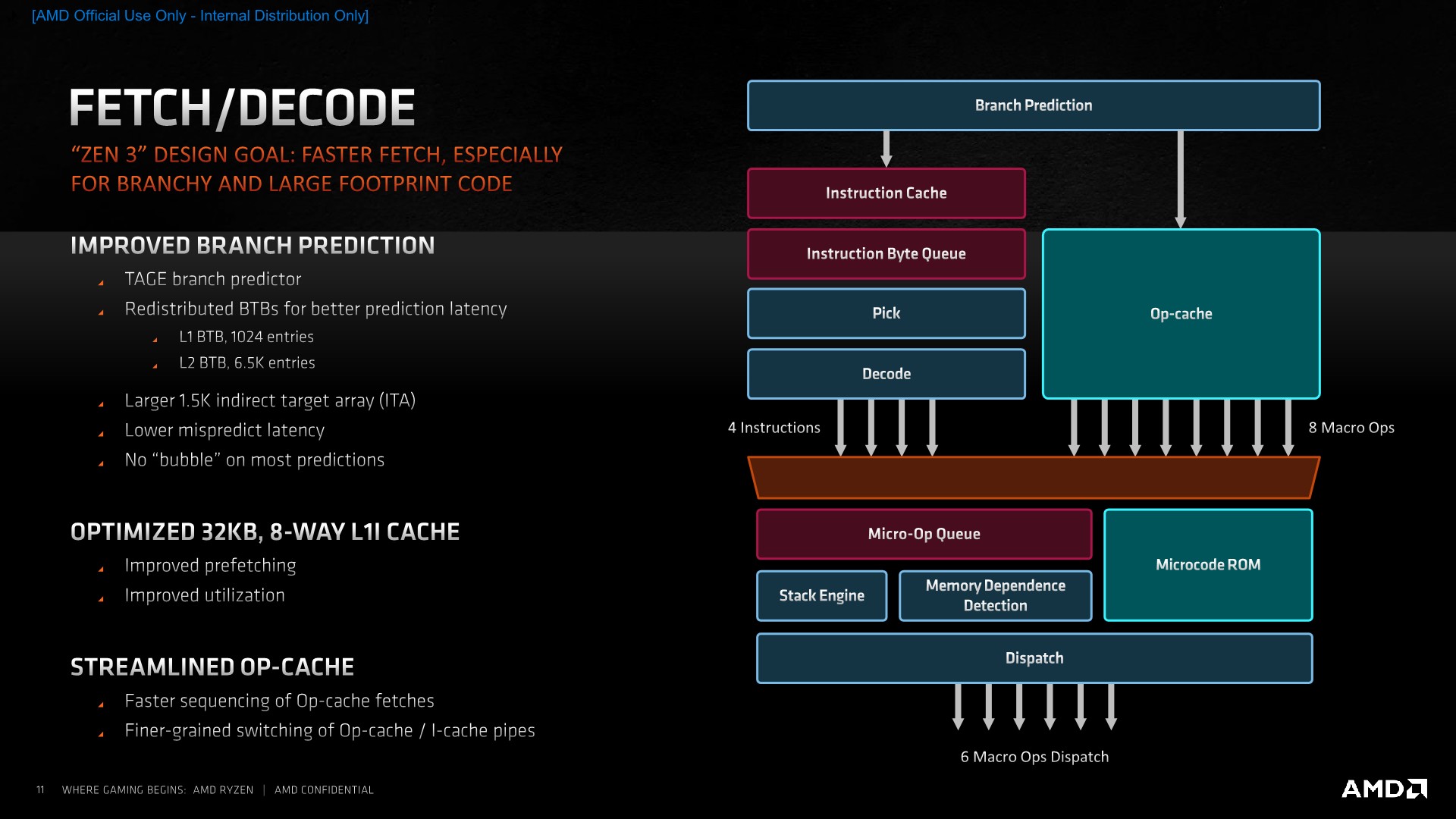
Improvements of the Zen3 cores in the actual blocks here include a faster branch predictor which is able to predict more branches per cycle. AMD wouldn’t exactly detail what this means but we suspect that this could allude to now two branch predictions per cycle instead of just one. This is still a TAGE based design as had been introduced in Zen2, and AMD does say that it has been able to improve the accuracy of the predictor.
Amongst the branch unit structure changes, we’ve seen a rebalancing of the BTBs, with the L1 BTB now doubling in size from 512 to 1024 entries. The L2 BTB has seen a slight reduction from 7K to 6.5K entries, but allowed the structure to be more efficient. The indirect target array (ITA) has also seen a more substantial increase from 1024 to 1536 entries.
If there is a misprediction, the new design reduces the cycle latency required to get a new stream going. AMD wouldn’t exactly detail the exact absolute misprediction cycles or how faster it is in this generation, but it would be a more significant performance boost to the overall design if the misprediction penalty is indeed reduced this generation.
AMD claims no bubbles on most predictions due to the increased branch predictor bandwidth, here I can see parallels to what Arm had introduced with the Cortex-A77, where a similar doubled-up branch predictor bandwidth would be able to run ahead of subsequent pipelines stages and thus fill bubble gaps ahead of them hitting the execution stages and potentially stalling the core.
On the side of the instruction cache, we didn’t see a change in the size of the structure as it’s still a 32KB 8-way block, however AMD has improved its utilisation. Prefetchers are now said to be more efficient and aggressive in actually pulling data out of the L2 ahead of them being used in the L1. We don’t know exactly what kind of pattern AMD alludes to having improved here, but if the L1I behaves the same as the L1D, then adjacent cache lines would then be pulled into the L1I here as well. The part of having a better utilisation wasn’t clear in terms of details and AMD wasn’t willing to divulge more, but we suspect a new cache line replacement policy to be a key aspect of this new improvement.
Being an x86 core, one of the difficulties of the ISA is the fact that instructions are of a variable length with encoding varying from 1 byte to 15 bytes. This has been legacy side-effect of the continuous extensions to the instruction set over the decades, and as modern CPU microarchitectures become wider in their execution throughput, it had become an issue for architects to design efficient wide decoders. For Zen3, AMD opted to remain with a 4-wide design, as going wider would have meant additional pipeline cycles which would have reduced the performance of the whole design.
Bypassing the decode stage through a structure such as the Op-cache is nowadays the preferred method to solve this issue, with the first-generation Zen microarchitecture being the first AMD design to implement such a block. However, such a design also brings problems, such as one set of instructions residing in the instruction cache, and its target residing in the OP-cache, again whose target might again be found in the instruction cache. AMD found this to be a quite large inefficiency in Zen2, and thus evolved the design to better handle instruction flows from both the I-cache and the OP-cache and to deliver them into the µOP-queue. AMD’s researchers seem to have published a more in-depth paper addressing the improvements.
On the dispatch side, Zen3 remains a 6-wide machine, emitting up to 6-Macro-Ops per cycle to the execution units, meaning that the maximum IPC of the core remains at 6. The Op-cache being able to deliver 8 Macro-Ops into the µOp-queue would serve as a mechanism to further reduce pipeline bubbles in the front-end – as the full 8-wide width of that structure wouldn’t be hit at all times.
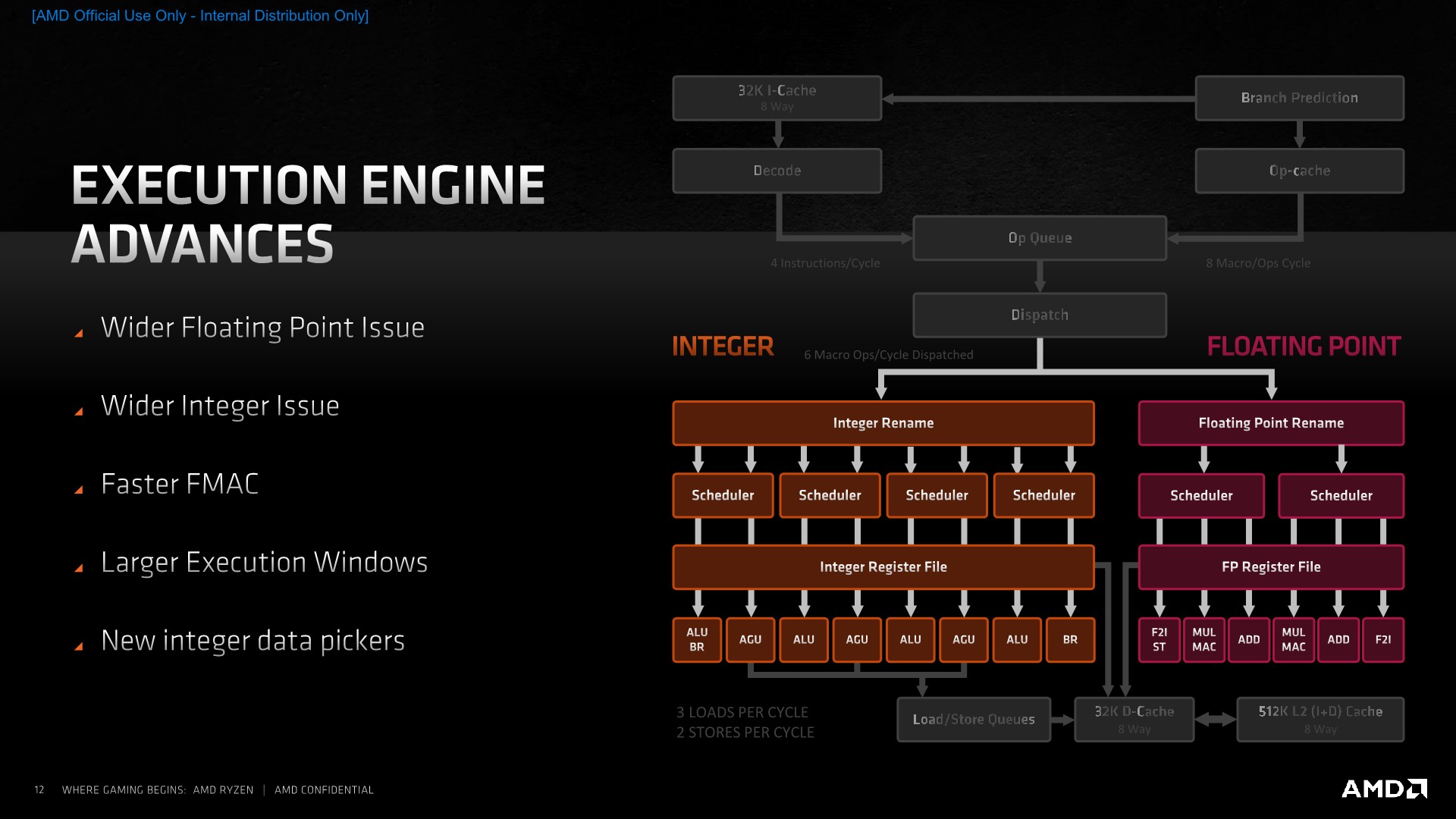
On the execution engine side of things, we’ve seen a larger overhaul of the design as the Zen3 core has seen a widening of both the integer and floating-point issue width, with larger execution windows and lower latency execution units.
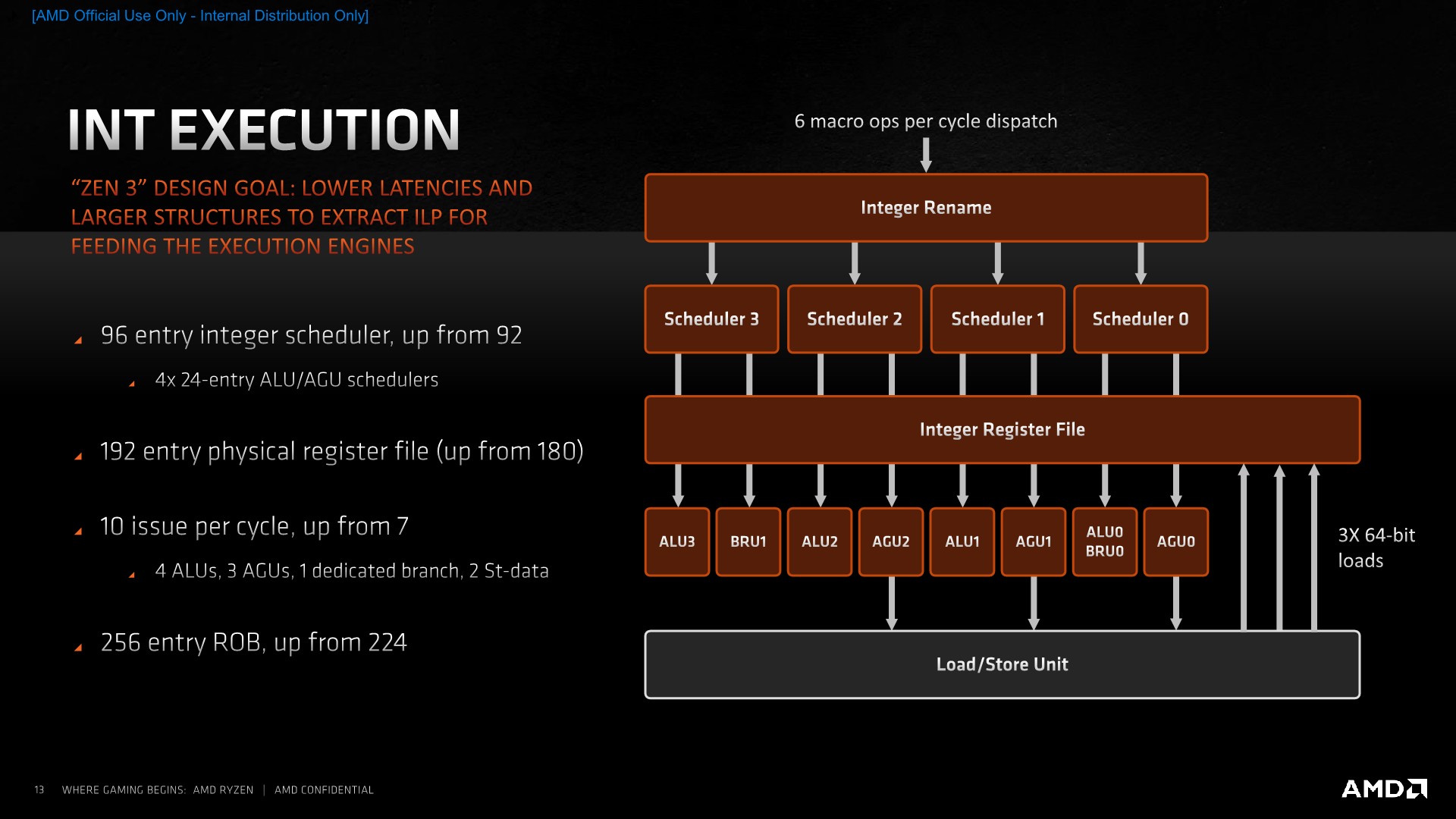

Starting off in more detail on the integer side, the one larger change in the design has been a move from individual schedulers for each of the execution units to a more consolidated design of four schedulers issuing into two execution units each. These new 24-entry schedulers should be more power efficient than having separate smaller schedulers, and the entry capacity also grows slightly from 92 to 96.
The physical register file has seen a slight increase from 180 entries to 192 entries, allowing for a slight increase in the integer OOO-window, with the actual reorder-buffer of the core growing from 224 instructions to 256 instructions, which in the context of competing microarchitectures such as Intel’s 352 ROB in Sunny Cove or Apple giant ROB still seems relatively small.
The overall integer execution unit issue width has grown from 7 to 10. The breakdown here is that while the core still has 4 ALUs, we’ve now seen one of the branch ports separate into its own dedicated unit, whilst the other unit still shares the same port as one of the ALUs, allowing for the unshared ALU to dedicate itself more to actual arithmetic instructions. Not depicted here is an additional store unit, as well as a third load unit, which is what brings us to 10 issue units in total on the integer side.
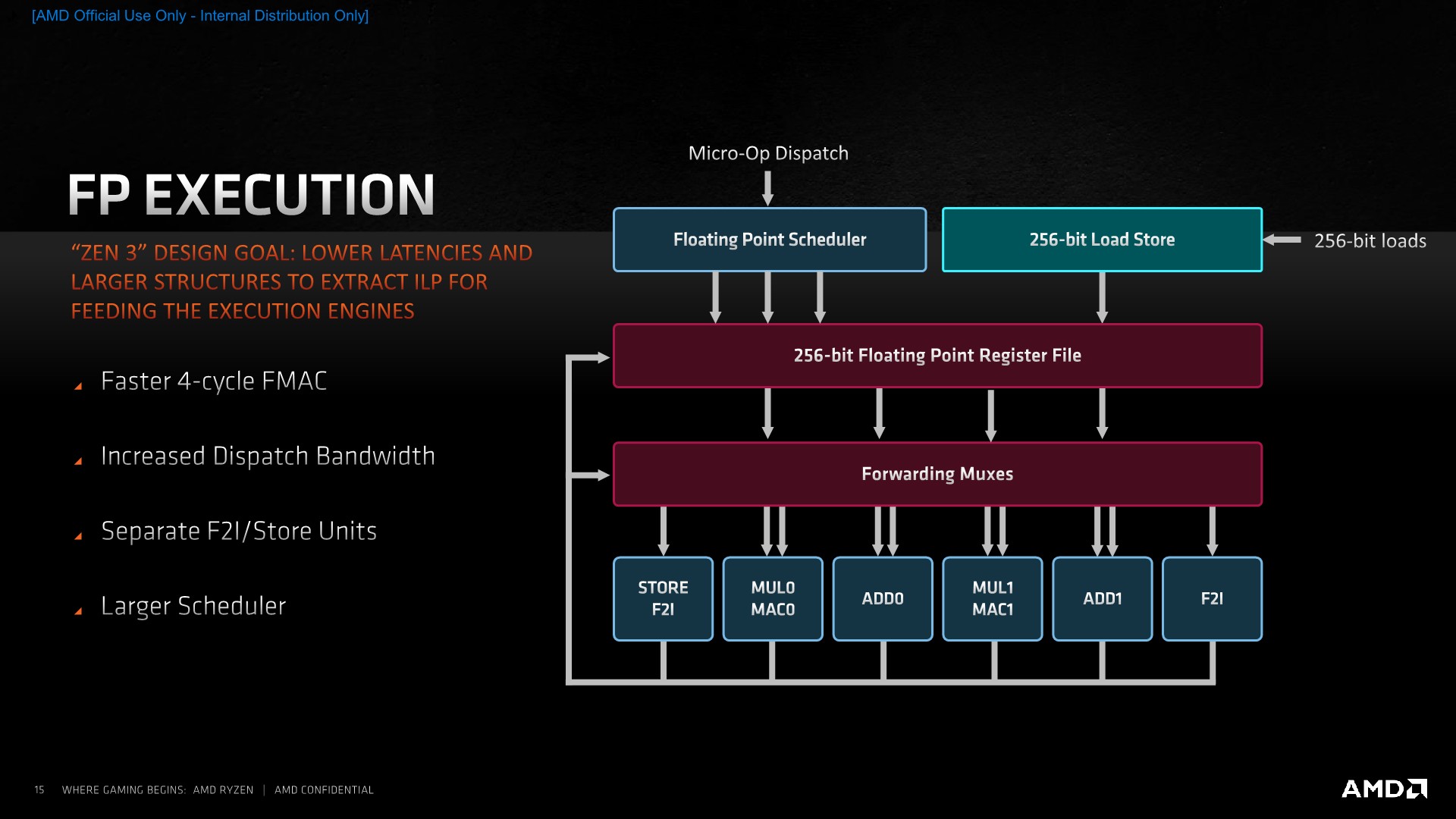
On the floating-point side, the dispatch width has been increased from 4 µOps to 6 µOps. Similar to the integer pipelines, AMD has opted to disaggregate some of the pipelines capabilities, such as moving the floating point store and floating-point-to-integer conversion units into their own dedicated ports and units, so that the main execution pipelines are able to see higher utilisation with actual compute instructions.
One of the bigger improvements in the instruction latencies has been the shaving off of a cycle from 5 to 4 for fused multiply accumulate operations (FMAC). The scheduler on the FP side has also seen an increase in order to handle more in-flight instructions as loads on the integer side are fetching the required operands, although AMD here doesn’t disclose the exact increases.








339 Comments
View All Comments
5j3rul3 - Thursday, November 5, 2020 - link
Rip Intel🤩🤩🤩Smell This - Thursday, November 5, 2020 - link
Chipzillah has got good stuff ... everyone is "just dandy" for the most part...
but, AMD has kicked Intel "night in the ruts" in ultimate price/performance with Zen3
Kangal - Saturday, November 7, 2020 - link
True, but the price hikes really hurt.For the Zen3 chips, it's only worth getting the:
- r9-5950X for the maximum best performance
- r5-3600X for the gaming performance (and decent value).
The 12 core r9-5900X is a complete no-buy. Whilst the r7-5800X is pretty dismal too, so both chips really need to be skipped. Neither of them have an Overclocking advantage. And there's just no gaming advantage to them over the 5600X. For more performance, get a 3950X or 5950X. And when it comes to productivity, you're better served with the Zen2 options. You can get the 3700 for much cheaper than the 5800X. Or for the same price you can get the 3900X instead.
Otherwise, if you're looking for the ultimate value, as in something better than the 5600X value... you can look at the 3600, 1600f, 3300X, 3100 chips. They're not great for gaming/single-core tasks, but they're competent and decent at productivity. Maybe even go into the Used market for some 2700X, 2700, 1800X, 1700X, 1700, 1600X, and 1600 chips as these should be SIGNIFICANTLY cheaper. Such aggressive pricing puts these options at better value for gaming (surprising), and better value for productivity (unsurprising).
DazzXP - Saturday, November 7, 2020 - link
Price hike doesn't really hurt that much, AMD was making very little money on their past Ryzen's because they had to contend with Intel Mindshare and throw more cores in as they did not quite have IPC and clock speeds, now they have all. It was as expected to be honest.Silma - Sunday, November 8, 2020 - link
Do you have any recommendations for motherboards for either a Zen3 or a Zen 2 (depending on availability of processors)? I want to spend as litte as possible on it, but it miust be compatible with 128 GB of RAM.AdrianBc - Sunday, November 8, 2020 - link
If you really intend to use 128 GB of RAM at some point in the future, you should use ECC RAM, because the risk of errors is proportional with the quantity of RAM.A good motherboard was ASUS Pro WS X570-ACE (which I use) previously at $300 but right now it is available at much higher prices ($370), for some weird reason.
If you want something cheap with 128 GB and ECC support, the best you can do is an ASRock micro-ATX board with the B550 chipset. There are several models and you should compare them. For example an ASRock B550M PRO4 is USD 90 at Amazon.
Silma - Wednesday, November 11, 2020 - link
Thanks for the input! Is ECC really necessary? The primary objective of the PC memory would be loading huge sound libraries in RAM for orchestral compositions. The PC would serve at the same time as gaming PC + Office PC.Spunjji - Sunday, November 8, 2020 - link
In the context of a whole system? Not really, no.In the context of an upgrade? Not at all, if you have a 4xx board you'll be good to go in January without having to buy a new board. That's something that hasn't been possible for Intel for a while, and won't be again until around March, when you'll be able to upgrade from a mediocre power hog of a chip to a more capable power hog of a chip.
Comparing new to used in terms of value of a *brand new architecture* doesn't really make much sense, but go for it by all means 👍 The fact remains that these have the performance to back up the cost, which you can see in the benchmarks.
leexgx - Sunday, November 8, 2020 - link
I would aim for the 5600x minimum unless your really trying to Save $100 as the 5600x is a good jump over the 3700x/3600xbiostud - Monday, November 9, 2020 - link
Uhm, no? For me the 5900X would make perfect sense. I game and work with/photo video editing, and would like to have my computer for a long time. The 5950X costs too much for my needs, the 5900X offers 50% more cores than the 5800X for $100 and the 5600X hasn't got enough cores when video editing. (Although I'm waiting for next socket before upgrading my 5820k)